Comet for NLP data problems¶
![]()
This example looks at sentiment classification using the Hugging Face library. Comet is integrated with the HuggingFace Trainer object and can automatically log parameters and metrics from this object.
To build this model, we will do the following:
- Download the IMDB sentiment dataset.
- Define a tokenizer and data collator to preprocess the data.
- Select our model for classification. In this case, we will be using
distilbert-base-uncased. - Define an evaluation function for our model where we compute the models metrics and log the confusion matrix.
- Train our model using the
Trainerobject.
Download the IMDB dataset¶
The first thing we're going to do is download the IMDB dataset using Hugging Face's datasets library.
from datasets import load_dataset
raw_datasets = load_dataset("imdb")
Select the model type for classification¶
Our pipeline will be defined around the model type that we're training. Let's set that now to distilbert-base-uncased.
PRE_TRAINED_MODEL_NAME = "distilbert-base-uncased"
Set up the tokenizer and data collator¶
Next, we're going to use the Hugging Face Transformer tokenizer and data collator for formatting our text data into input tokens and padding them to uniform length.
from transformers import AutoTokenizer, Trainer, TrainingArguments
from transformers import DataCollatorWithPadding
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_MODEL_NAME)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Create a sample dataset¶
For this example, we will only use a sample (that is, 1000 examples) from the total dataset.
train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
Set up the transformer model¶
Take advantage of Comet's integration with the transformers library.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(PRE_TRAINED_MODEL_NAME, num_labels=2)
Set up the evaluation function¶
Here, we're going to define the code for our evaluation metrics and for logging a confusion matrix to Comet.
We're going to pass the compute_metrics function to our Trainer which will, in turn, call this function at the end of every epoch and log the resulting metrics to Comet. Comet will automatically log metrics such as loss, eval_loss etc from the Trainer.
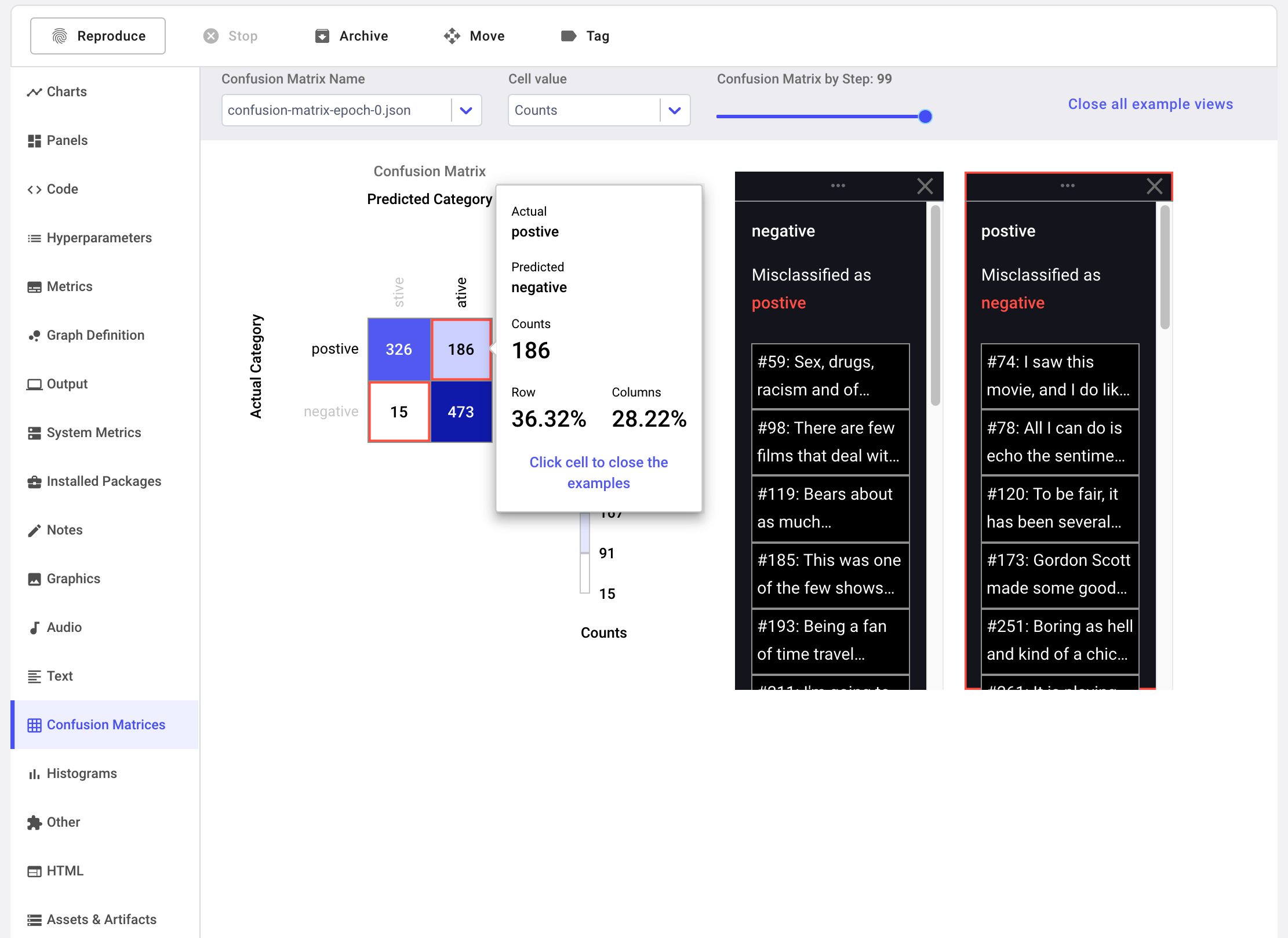
We will also log our model predictions to Comet's Confusion Matrix.
The confusion matrix also gives us the option of logging examples from our dataset. We're going to log these as well to give our predictions more context.
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def get_example(index):
return eval_dataset[index]['text']
def compute_metrics(pred):
experiment = comet_ml.get_global_experiment()
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='macro')
acc = accuracy_score(labels, preds)
if experiment:
epoch = int(experiment.curr_epoch) if experiment.curr_epoch is not None else 0
experiment.set_epoch(epoch)
experiment.log_confusion_matrix(
y_true=labels,
y_predicted=preds,
file_name=f"confusion-matrix-epoch-{epoch}.json",
labels=['negative', 'postive'],
index_to_example_function=get_example
)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
Run training¶
Comet works easily with third-party libraries that can be used to train models. In this case, we will use the Trainer object from the Transformers library.
You can configure how Comet logs an Experiment from the Trainer using a set of environment variables. In this case, we will set COMET_MODE to Online to stream our metrics directly to the UI. We're also going to set the COMET_LOG_ASSETS variable to TRUE so that our trained model is logged as an asset in our Experiment.
export COMET_MODE=ONLINE
export COMET_LOG_ASSETS=TRUE
Finally, we are ready to train our model.
training_args = TrainingArguments(
seed=42,
output_dir='./results',
overwrite_output_dir=True,
num_train_epochs=1,
eval_steps=100,
evaluation_strategy="steps",
save_total_limit=10,
save_steps=100,
do_train=True,
do_eval=True
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
data_collator=data_collator,
)
trainer.train()
Clicking the off-diagonal cells in the confusion matrix displays a window with information about misclassified examples.
Try it out!¶
We have prepared a Colab Notebook that you can use to run the example yourself. ![]()
More examples¶
Other typical end-to-end examples showcase how Comet is used to handle the challenges presented by structured data and image data.